全景视觉的Depth Anything来了!Insta360推出DAP,200万数据打造全场景360°空间智能新高度
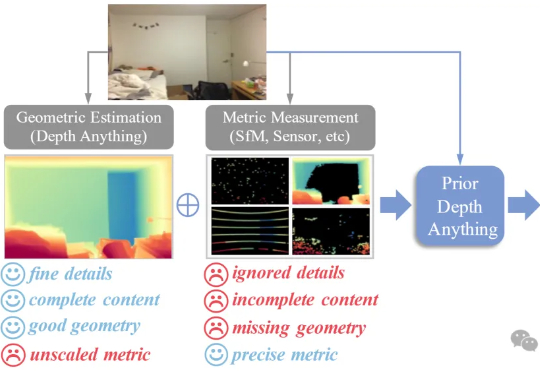
全景视觉的Depth Anything来了!Insta360推出DAP,200万数据打造全场景360°空间智能新高度在空间智能(Spatial Intelligence)飞速发展的今天,全景视角因其 360° 的环绕覆盖能力,成为了机器人导航、自动驾驶及虚拟现实的核心基石。然而,全景深度估计长期面临 “数据荒” 与 “模型泛化差” 的瓶颈。
来自主题: AI技术研报
7192 点击 2025-12-30 09:57